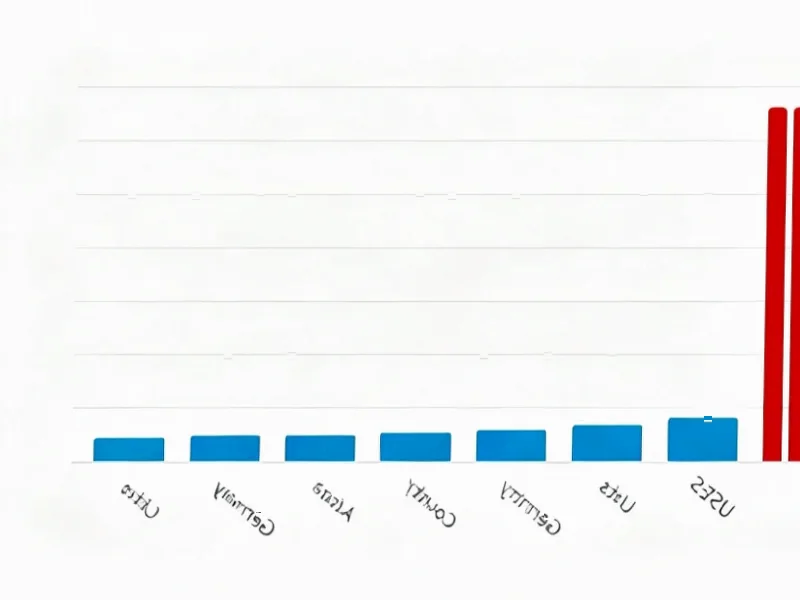
According to ZDNet, a major Cloudflare outage on Tuesday morning disrupted services including X, ChatGPT, Spotify, and League of Legends, with reports spiking just before 7 a.m. ET. The incident generated over 330,000 global outage reports for Cloudflare and 267,000 for X alone before the company implemented a fix around 10 a.m. ET. Cloudflare confirmed the “internal service degradation” on its status page and deployed dashboard service restoration by 9:34 a.m. ET. The outage affected users worldwide, with more than 38,000 reports from the US and 35,674 from Great Britain. Even downdetector.com, the popular outage tracking site, was temporarily inaccessible due to the Cloudflare issues.


The disturbing pattern of infrastructure failures
Here’s the thing that should worry everyone: this isn’t the first time Cloudflare has had major problems this year, and it feels eerily similar to the massive CrowdStrike outage that paralyzed businesses last year. We’re building this incredibly interconnected internet where one company’s hiccup can take down hundreds of major services simultaneously. And when even the outage tracking sites go down because of the outage they’re supposed to be tracking, you know we’ve got a problem.
Think about it – Cloudflare’s entire value proposition is making sites faster and more reliable through their content delivery network and security services. But when their own infrastructure fails, it creates this cascading effect that takes down everything from social media platforms to AI tools to music streaming services. The irony is almost too perfect.
What this means for businesses
For companies relying on third-party infrastructure providers, these recurring outages should be a wake-up call. When your entire online presence can vanish because of someone else’s technical issues, you’ve got to ask yourself: is putting all our eggs in one basket really the smartest strategy?
Basically, we’re seeing the downside of the hyper-consolidated cloud ecosystem. Services like Downdetector becoming temporarily useless during the very outages they exist to monitor shows just how deep these dependencies run. Businesses need to seriously consider redundancy strategies rather than assuming any single provider, no matter how reliable they claim to be, will never fail.
The bigger picture
Cloudflare eventually got things sorted out, updating their status page with the all-clear around 10 a.m. But the fact that we’re seeing multiple major infrastructure failures in quick succession suggests something systemic might be going on. Are these companies growing faster than their operational capabilities? Is the complexity of modern internet infrastructure reaching a breaking point?
One thing’s for sure – as more critical services move online, the stakes for these outages keep getting higher. What happens when it’s not just your Spotify playlist that goes down, but hospital systems or emergency services? The cloud broke today, and it’ll probably break again. The question is whether we’re learning anything from these repeated failures.